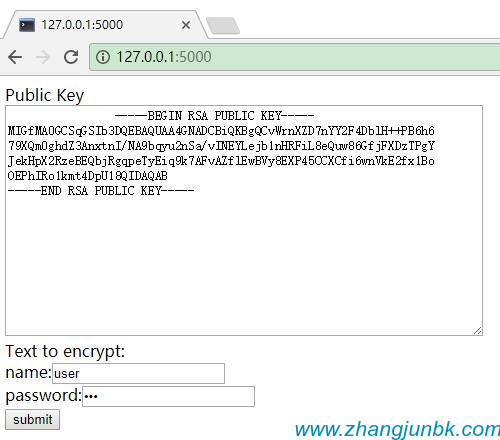
本文實例講述了Flask框架實現的前端RSA加密與后端Python解密功能。分享給大家供大家參考,具體如下:前言在使用Flask開發(fā)用戶登錄API的時候,我之前都是明文傳輸username和password。這種傳輸方式有一定的安全隱患,password可能會在傳輸過程中被竊聽而造成用戶密碼的泄漏。那么我認為解決該問題的方法是這樣的:在前端頁面對數據進行加密,然后再發(fā)送到后端進行處理。這一篇文章是前端用RSA的publicKey進行加密,然后后端用Pyth
系統(tǒng) 2019-09-27 17:57:34 6423
在字符前后補字符,經常會有比如讀取Excel的數據0000XX,讀出來是XX,那要在前被0
張軍 2019-11-02 14:16:45 5502
python的四舍五入有問題,所以進行自己重寫啦
張軍 2019-11-02 14:14:33 5440
數組批量轉換,用于多線程比較有用,或分批進行數據處理比較有用
張軍 2019-11-02 14:17:51 5432
df = pd.read_csv(path='file.csv')
參數:header=None 用默認列名,0,1,2,3...
names=['A', 'B', 'C'...] 自定義列名
index_col='A'|['A', 'B'...] 給索引列指定名稱,如果是多重索引,可以傳list
skiprows=[0,1,2] 需要跳過的行號,從文件頭0開始,skip_footer從文件尾開始
nrows=N 需要讀取的行數,前N行
chunksize=M 返回迭代類型TextFileReader,每M條迭代一次,數據占用較大內存時使用
sep=':'數據分隔默認是',',根據文件選擇合適的分隔符,如果不指定參數,會自動解析
skip_blank_lines=False 默認為True,跳過空行,如果選擇不跳過,會填充NaN
converters={'col1', func} 對選定列使用函數func轉換,通常表示編號的列會使用(避免轉換成int)
dfjs = pd.read_json('file.json') 可以傳入json格式字符串
d
張軍 2019-10-16 23:13:02 5408
ambda函數,返回列表的第二個元素f=lambdax:x[1]f([1,2])輸出的是2
系統(tǒng) 2019-09-27 17:49:10 26365
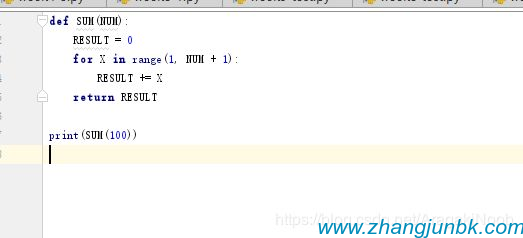
Python源文件改寫。編寫一個程序,讀取一個Python源程序文件source.py,將文件中所有除保留字外的小寫字母換成大寫字母。生成后的文件要能夠被Python解釋器正確執(zhí)行。我不知道還有什么其他方法可以從列表中把單詞逐個分離出來所以我用了jieba庫測試文件名:source.py(將此文件放在主程序相同目錄)defsum(num):result=0forxinrange(1,num+1):result+=xreturnresultprint(sum
系統(tǒng) 2019-09-27 17:57:23 11531
python中struct.unpack的用法4/25/200912:18:21PMPython中按一定的格式取出某字符串中的子字符串,使用struck.unpack是非常高效的。1.設置fomat格式,如下:#取前5個字符,跳過4個字符華,再取3個字符format='5s4x3s'2.使用struck.unpack獲取子字符串importstructprintstruct.unpack(format,'Testastring')#('Test','ing
系統(tǒng) 2019-08-29 22:45:17 10279
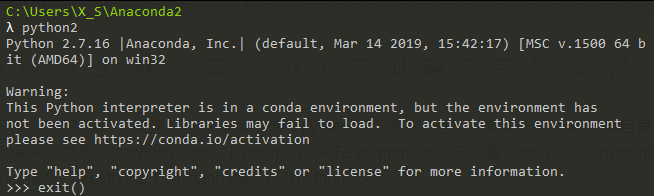
以下問題是針對:“Warning:ThisPythoninterpreterisinacondaenvironment,buttheenvironmenthasnotbeenactivated.Librariesmayfailtoload.Toactivatethisenvironmentpleaseseehttps://conda.CommandNotFoundError:Yourshellhasnotbeenproperlyconfiguredtous
系統(tǒng) 2019-09-27 17:57:09 9690
編寫程序,生成包含1000個0~100之間的隨機整數,統(tǒng)計并輸出每個整數出現的次數。importrandomls=list()ls=[random.randint(0,100)foriinrange(1000)]st=set(ls)foriinst:print(i,'出現的次數為:',ls.count(i))運行結果:
系統(tǒng) 2019-09-27 17:47:42 9239
搜了網上一些關于如何在python中實現海康威視相機的連接與畫面播放的資料,最直接的方式是通過rtsp流來實現。海康的rtsp協(xié)議格式如下(參考:海康相機使用RTSP):rtsp://[username]:[passwd]@[ip]:[port]/[codec]/[channel]/[subtype]/av_stream主碼流:rtsp://admin:12345@192.168.1.64:554/h264/ch1/main/av_streamrtsp:
系統(tǒng) 2019-09-27 17:56:37 9096
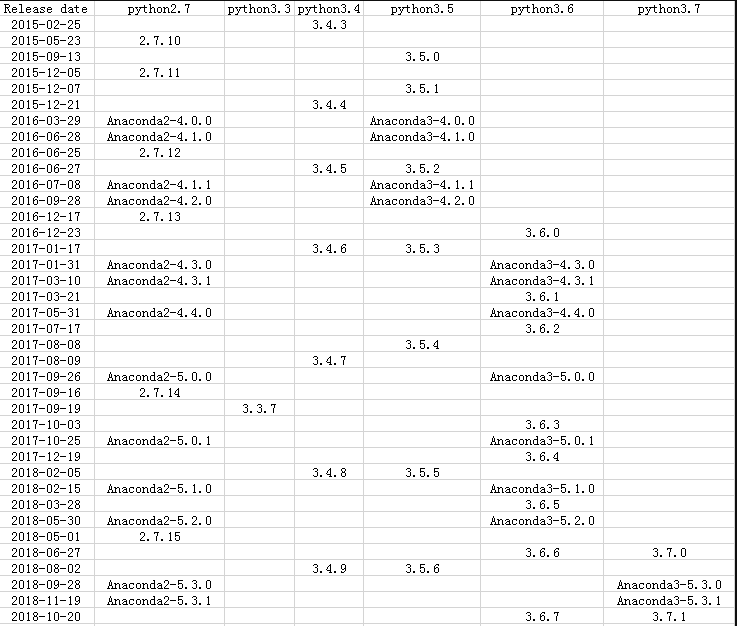
一、對應版本首先解釋一下上表。anaconda在每次發(fā)布新版本的時候都會給python3和python2都發(fā)布一個包,版本號是一樣的。表格中,python版本號下方的離它最近的anaconda包就是包含它的版本。舉個例子,假設你想安裝python2.7.14,在表格中找到它,它下方的三個anaconda包(anaconda2-5.0.1、5.1.0、5.2.0)都包含python2.7.14;假設你想安裝python3.6.5,在表格中找到它,它下方的an
系統(tǒng) 2019-09-27 17:56:50 8341
思路:1.在這里創(chuàng)建了兩個函數,一個是求最大公約數的函數gongyueshu(a,b),一個是求最小公倍數的函數gongbeishu(a,b)2.求最大公約數,在1到a,b之間最小的數之間遍歷,找出可以同時整除a,b的數,并將其賦值給gongyueshu.循環(huán)多次后,越來越大的公約數被賦值給gongyueshu,最后返回最大的公約數3.求最小公倍數,另c=a*b,遍歷1到c之間的所有數,找出可以同時被a,b整除的數,這個數就是最小公倍數,跳出循環(huán),返回最小
系統(tǒng) 2019-09-27 17:47:17 8001
在使用selenium進行登錄操作練手時,發(fā)現登錄按鈕是用ahref="javascript.void(0)"實現的,于是按照習慣思維進行點擊a=soup.find_all('a')fornamesina:try:print(names['href'])ifnames['href']=="javascript:void(0);":print"IMINHUR"names.click()breakexcept:continue發(fā)現無法點擊,提示names沒有那
系統(tǒng) 2019-09-27 17:56:00 7457
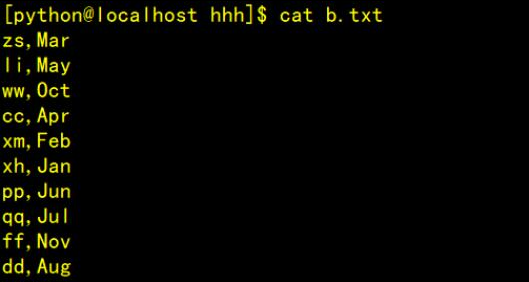
示例數據:zs,3li,5ww,10cc,4xm,2xh,1pp,6qq,7ff,11dd,8kk,12mm,9處理后效果:腳本代碼如下:創(chuàng)建文件名.py腳本文件fo=open("/home/python/hhh/a.txt","r")print("文件名為:",fo.name)a=[]forlineinfo:a.append(line)f01=open("/home/python/hhh/b.txt","a")forindexinrange(len(a)
系統(tǒng) 2019-09-27 17:37:40 6527