最近用Java寫了一個小工具,想將它達成exe執行文件,到時候直接放某個目錄下,一執行就能跑啦。
用到的工具:
1、寫好的項目:可以是java項目,也可以是java web項目
2、能夠打jar的工具:我用的MyEclipse開發,他們有自帶的工具,我就直接用這個了
3、exe4j:可以去網上下載,地址:https://exe4j.apponic.com/download/,有綠色版的和安裝的,32位和64位的。我的是別人給的安裝版的,跟官網的最新版可能有些出入,有需要的可以去附件中下載。
4、jre:java項目的運行離不開jre,也不能要求客戶自己去裝JDK,所以還是給它帶個比較保險。(JDK安裝之后,有jdk和jre兩個目錄,可以直接復制這個jre文件夾,也可以復制jdk文件夾下的jre。我這里用的jdk是1.6的)。
5、一張后綴名為ico的圖標文件,作為exe執行程序的圖標。也可以沒有。
下面開始弄。
張軍 2020-03-18 20:31:12 5688
C++是C語言的繼承,它既可以進行C語言的過程化程序設計,又可以進行以抽象數據類型為特點的基于對象的程序設計,還可以進行以繼承和多態為特點的面向對象的程序設計。C++擅長面向對象程序設計的同時,還可以進行基于過程的程序設計,因而C++就適應的問題規模而論,大小由之。
C++不僅擁有計算機高效運行的實用性特征,同時還致力于提高大規模程序的編程質量與程序設計語言的問題描述能力。
張軍 2019-11-21 08:40:30 5603
在字符前后補字符,經常會有比如讀取Excel的數據0000XX,讀出來是XX,那要在前被0
張軍 2019-11-02 14:16:45 5544
工具類下載(java工具類匯總.zip),下載后即可使用
java工具類匯總
日期工具類
excel工具類
反向ajax工具類
加密工具類
ftp工具類
http工具類
java工具類
資源文件工具類
拼音工具類
反射工具類
分頁工具類
排序工具類
連接超時工具類
xml工具類(互相轉換map,list等)
樹工具類
正則表達式工具類
內存查詢工具類
freemarker工具類
壓縮解壓縮工具類
io工具類
JSON工具類
條形碼工具類
緩存工具類
證書工具類
張軍 2019-08-15 16:31:31 5506
python的四舍五入有問題,所以進行自己重寫啦
張軍 2019-11-02 14:14:33 5491
數組批量轉換,用于多線程比較有用,或分批進行數據處理比較有用
張軍 2019-11-02 14:17:51 5463
df = pd.read_csv(path='file.csv')
參數:header=None 用默認列名,0,1,2,3...
names=['A', 'B', 'C'...] 自定義列名
index_col='A'|['A', 'B'...] 給索引列指定名稱,如果是多重索引,可以傳list
skiprows=[0,1,2] 需要跳過的行號,從文件頭0開始,skip_footer從文件尾開始
nrows=N 需要讀取的行數,前N行
chunksize=M 返回迭代類型TextFileReader,每M條迭代一次,數據占用較大內存時使用
sep=':'數據分隔默認是',',根據文件選擇合適的分隔符,如果不指定參數,會自動解析
skip_blank_lines=False 默認為True,跳過空行,如果選擇不跳過,會填充NaN
converters={'col1', func} 對選定列使用函數func轉換,通常表示編號的列會使用(避免轉換成int)
dfjs = pd.read_json('file.json') 可以傳入json格式字符串
d
張軍 2019-10-16 23:13:02 5457
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構。
用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力進行高速運算和存儲。
Hadoop實現了一個分布式文件系統(Hadoop Distributed File System),簡稱HDFS。HDFS有高容錯性的特點,并且設計用來部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)來訪問應用程序的數據,適合那些有著超大數據集(large data set)的應用程序。HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streaming access)文件系統中的數據。
Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS為海量的數據提供了存儲,而MapReduce則為海量的數據提供了計算。
張軍 2019-08-20 20:29:55 5301
基于java實現的仿qq即時通訊工具
張軍 2019-10-14 20:41:25 5149
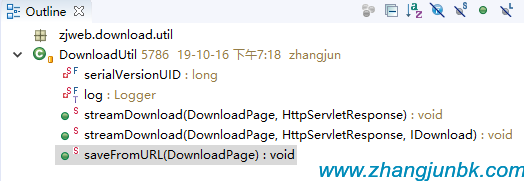
網絡文件下載
下載文件-通過流
保存文件-網絡文件
張軍 2019-10-16 19:21:49 4857
樹工具類
張軍 2022-03-12 16:50:03 3773
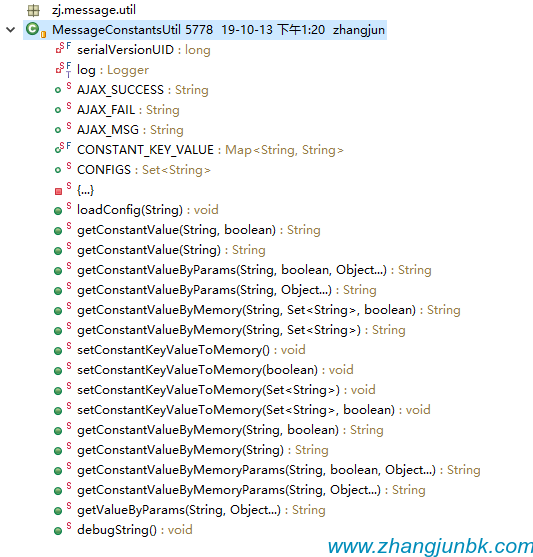
常量資源文件工具類,讀取配置文件常量的工具類,可放入內存,速度及快
張軍 2019-10-14 22:00:32 3725
分割email地址轉換成一行
判斷系統
中文數字轉數字
張軍 2022-03-06 12:31:55 3155
注入工具類
張軍 2022-03-09 21:23:20 2783
ambda函數,返回列表的第二個元素f=lambdax:x[1]f([1,2])輸出的是2
系統 2019-09-27 17:49:10 26445